Zautomatizujte si linkbuilding expirovaných domén
8 minut čtení

Jednou z taktik, jak budovat odkazový profil, je nákup expirovaných domén s dobrým odkazovým profilem (tedy odkazů vedoucích z relevantních a kvalitních webů) a jejich přesměrování. Taktika je poměrně známá, avšak ne moc oblíbená z důvodu své náročnosti.
Takové domény musíme najít, zkontrolovat jejich dostupnost a kvalitu odkazového profilu. Časově jsou tyto kroky poměrně náročné a rutinní. Pro klienta je to aktivita, která finančně nemusí dávat smysl a raději investuje prostředky do jiných linkbuildingových taktik.
Proto mne napadlo usnadnit si práci skriptem a ušetřit tak hromadu času a energie na náročnější úkoly. Běžně na kvalitní a expirovanou doménu, která je vhodná ke koupi, narazíte párkrát do roka. Takto celý rok zvládneme během jednoho odpoledne.
Nastavte si ho také! Řeknu vám jak.
Nastavení skriptu od A do Z
- Stáhněte si v Microsoft Store program Ubuntu (ano, jmenuje se stejně jako distribuce od Linuxu) a po instalaci restartujte systém. Po restartu otevřete program Ubuntu – zobrazí se vám terminál.
- Pokud nevíte, jak příkazový řádek ovládat, sepsali jsme pár základních příkazů.
- Na webu www.monitoruju.net zadejte do vyhledávacího pole váš email a klíčová slova, která chcete mít v názvu domény. Volte raději přesné termíny než pouhé kořeny slov, vyhnete se řádce nerelevantních domén, které byste museli procházet.
- Do vašeho e-mailu mezitím dorazily seznamy domén. V terminálu si otevřete soubor pomocí příkazu nano url.txt a následně do něj nakopírujte seznam domén z e-mailu (1 řádek = 1 doména). Následně soubor zavřete pomocí klávesové zkratky CTRL+X a zmáčkněte klávesu Y pro uložení změn.
- Spusťte skript sh edit_url. Ten vytvoří URL adresy ve tvaru https://www.nic.cz/whois/domain/
/ . URL adresy se uloží do souboru edited_url.txt - Následně spusťte skript sh crawling.
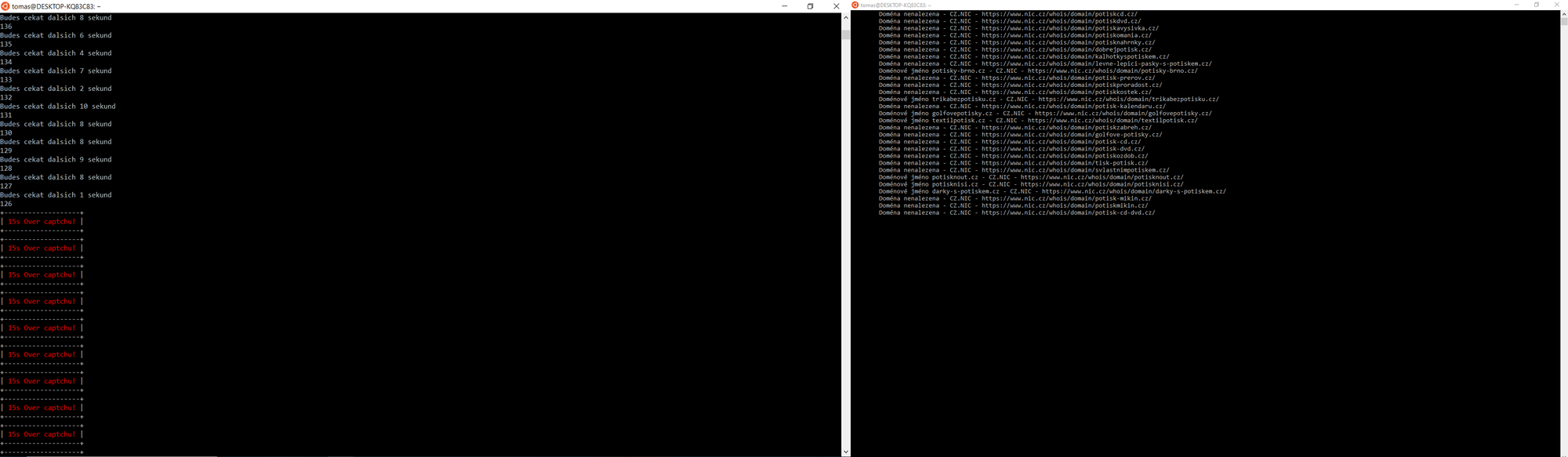
- Po spuštění skriptu se začnou scrapovat informace o dostupnosti domén, které se uloží do souboru domain_info.txt.
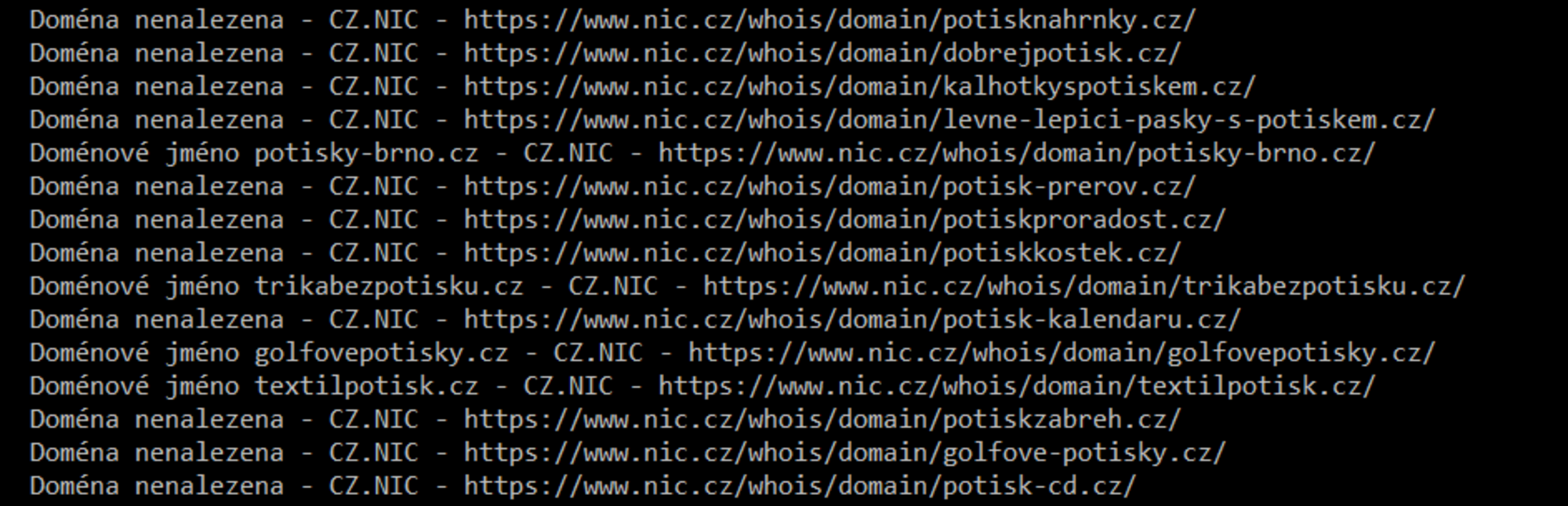
Výstup ze souboru domain_info.txt - Po zhruba 50 požadavcích odeslaných na doménu nic.cz se zobrazí captcha, kterou je potřeba vyplnit. Skript na tuto situaci upozorní a dává 15 s pauzu na vyplnění captchi. V případě, že se nevyplní, tak čeká dále (reálně zkontroluje, jestli může pokračovat obyčejným dotazem, a pokud se mu vrátí špatná hodnota, tak znovu čeká 15 s)
- Nezapomeňte mít stále otevřené okno stránky nic.cz třeba s touto URL adresou a captchu vždy vyplnit. Skript nemusíte vypínat a zapínat, sám bude v aktivitě pokračovat.
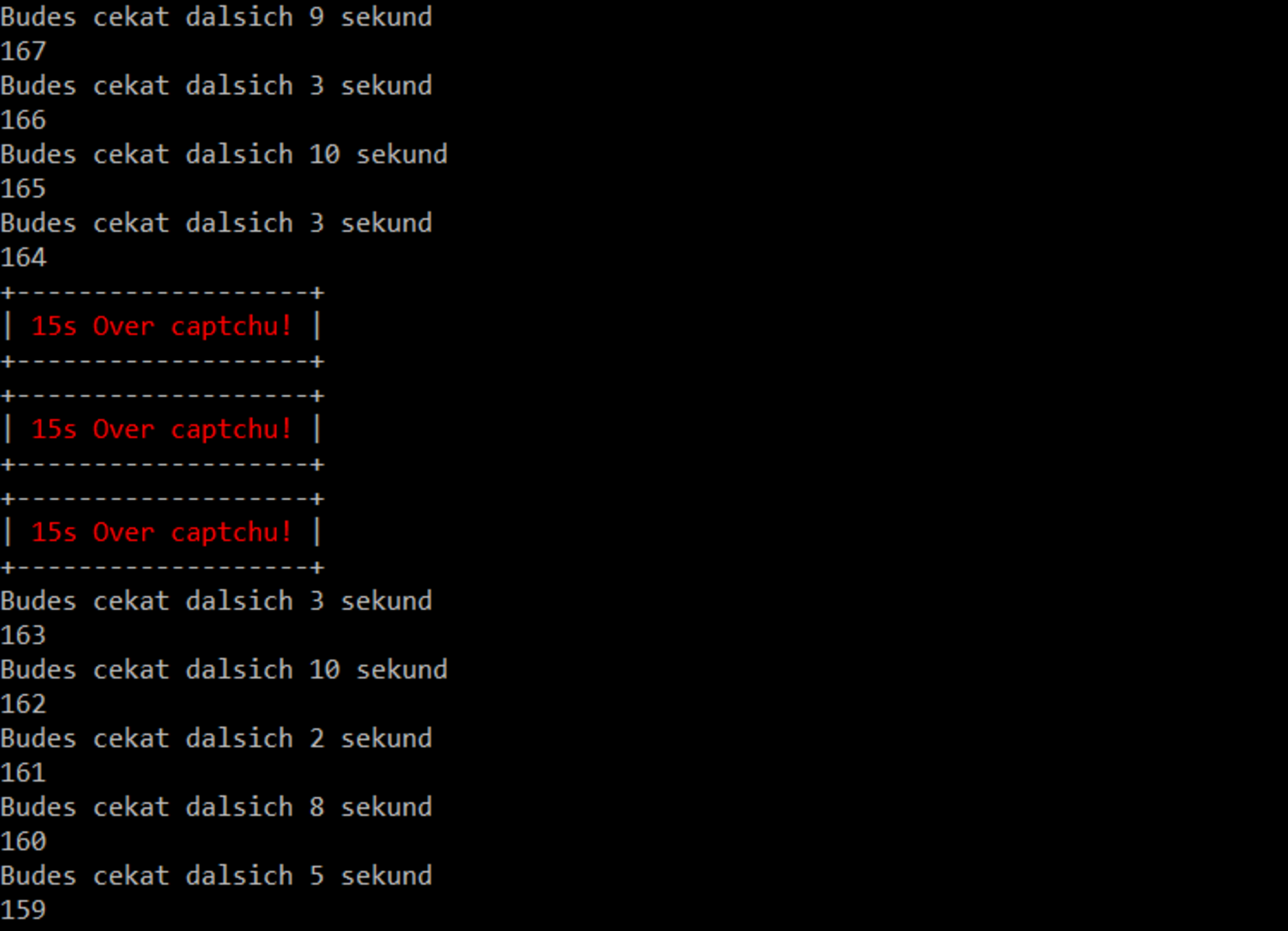
Výstup spuštěného skriptu „crawling“ – captchu jsme ověřili až po 1 minutě. 
Nic.cz - ukázka ověření captchi - Skript crawling při scrapování zobrazuje dobu, po jakou bude čekat (viz screenshot výše). Ta je náhodná – od 1 do 10 sekund. Důvody čekání:
- nezahltíte server,
- předejdete blokování vaší IP adresy.
Skript také ukazuje počet URL adres, které plánuje projít – v tomto případě se jednalo o 159 URL adres/domén. Maximální doba, po kterou skript poběží je zhruba půl hodiny.
Po dokončení skriptu crawling se výstup uloží do domain_info.txt. Data z něj překopírujte do Excelu.
- Domény, které jsou již zabrané, začínají textací Doménové jméno. Ty odstraňte pomocí filtru – zvolte například klíčové slovo „jméno“.
- Názvy domén zbavte přebytečného textu pomocí klávesové zkratky CTRL+H. Řetězec textu „Doména nenalezena – CZ.NIC – https://www.nic.cz/whois/domain/“ smažte (a jelikož text nechceme v této funkci ničím nahrazovat, tak druhé pole ponecháme prázdné – tím dojde k odstranění). Stejným způsobem odstraňte trailing slash (lomítko na konci řádku).
- Zbydou vám očištěné domény, které nejsou zabrané. Teď musíte ověřit stav jejich odkazového profilu.
Zjistěte stav odkazového profilu
- Vysledné domény zkopírujte a vložte je do Ahrefs do nástroje Batch Analysis (případně do jiného nástroje, který umí totéž).
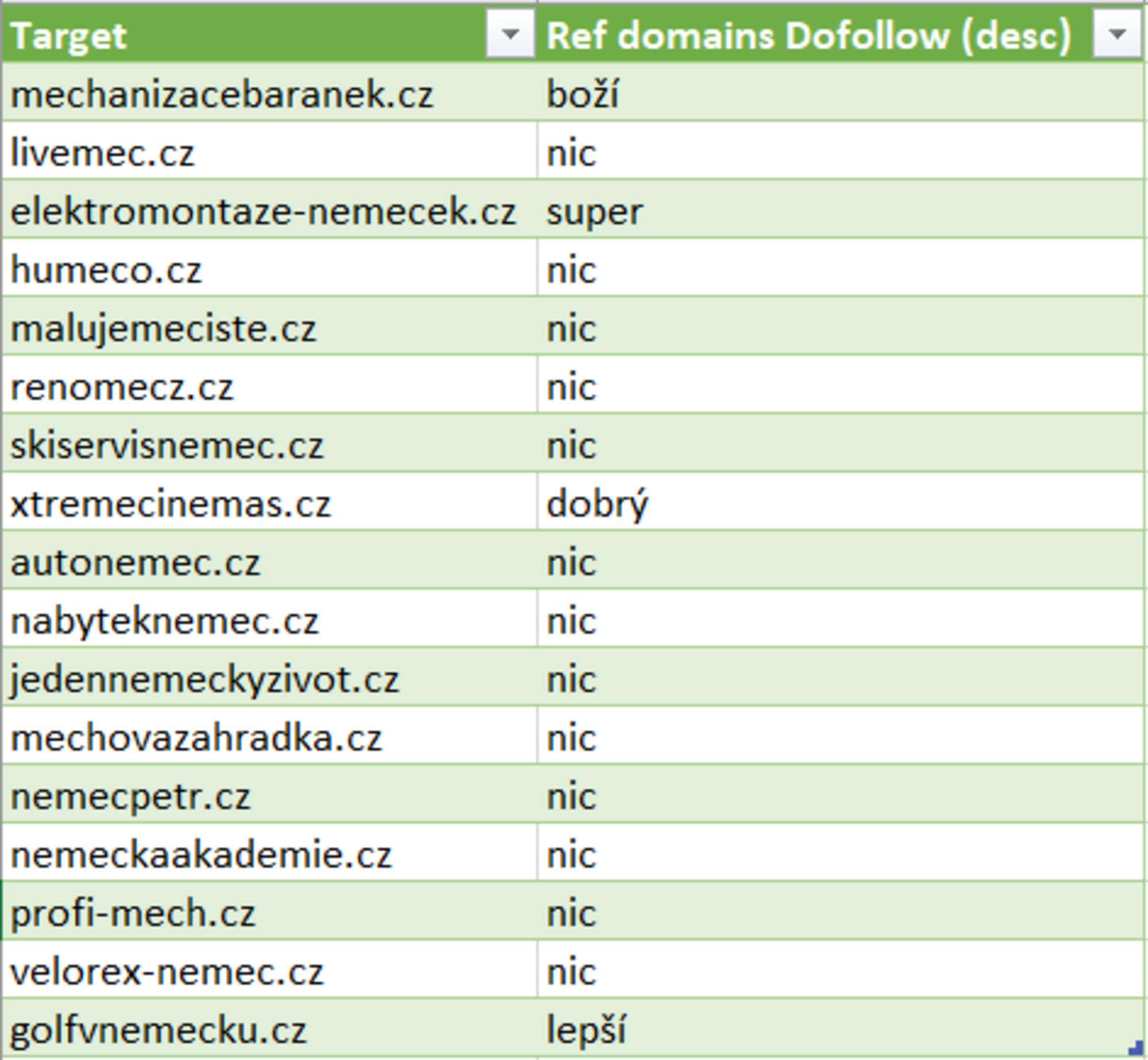
Poznámka: Nástroj zvládne zpracovat pouze omezený počet domén dle zvoleného tarifu. - Výstup z nástroje stáhněte a otevřete jej v Excelu. Přes funkci Vlookup doplňte hodnoty ze sloupce Dofollow, aby výstup vypadal takto:
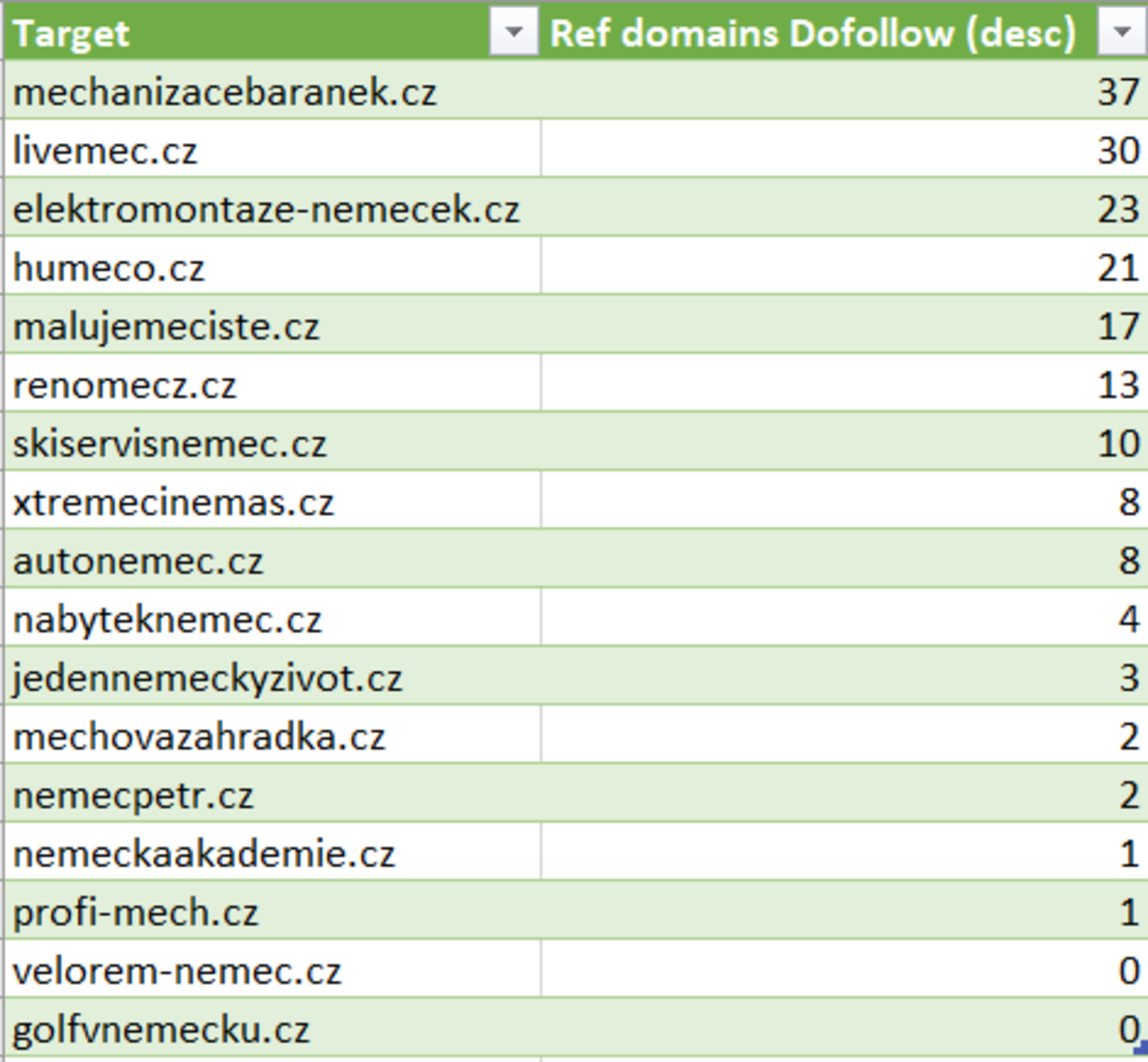
Výstup z Bach Analysis – Ahrefs - Ke každé doméně doplňte počet dofollow odkazů a seřaďte je sestupně. Odkazy s hodnotou 0 rovnou smažte – nemají pro nás žádný význam.
- Vyberte prvních x domén a znovu je překopírujte do Ahrefs do nástroje Batch Analysis a podrobně prozkoumejte jejich odkazové profily – vždy nás zajímají domény s relevantními a kvalitními odkazy (například: mvcr.cz, aktualne.cz, zive.cz, seznam.cz, seznamzpravy.cz, blogy atp.).
- Tento výběr domén následně ohodnoťte podle kvality do různých segmentů – budete vědět, které domény máte řešit s klientem prioritně.
Segmentace domén podle odkazového profilu
Příkazy
nano url.txt – otevře soubor v editoru. Klávesovou zkratkou ctrl+x jej zavřete a vyvoláte další akci:
- zmáčknutím „y“ soubor uložíte,
- klávesou „n“ jej opustíte bez uložení,
- „c“ vás vrátí zpátky do editoru.
sh crawling – spustí skript.
- Běžící skript klávesovou zkratkou ctrl+c vypnete.
tail -f domain_info.txt – zobrazí obsah souboru v reálném čase; každý nově přidaný řádek se hned zobrazí v terminálu.
- Alternativně můžete použít cat domain_info.txt – příkaz vypíše jednorázově celý obsah souboru.
- Doporučujeme otevřít program Ubuntu v novém okně, kde tento příkaz tail -f spustíte.
Skripty
edit_url
Tento skript vytvoří seznam URL adres, které následně prozkoumá skript crawling.
#! /bin/bash#rm edited_url.txtwhile read linedoecho "https://www.nic.cz/whois/domain/$line/" >> edited_url.txtdone < url.txt
crawling
Skript crawling prozkoumá soubor edited_url.txt řádek po řádku, který jste vytvořili pomocí skriptu edit_url (viz výše). Ze stažených odpovědí ze serveru extrahujeme pouze jednu informaci – zda je doména zabraná nebo ne. Negativní i pozitivní odpovědi skript uloží do souboru domain_info.txt.
#! /bin/bash
count=$(wc -l < edited_url.txt)
RED='\033[1;31m'
NC='\033[0m'
#rm domain_info.txt
while read line
do
info=$(curl -s $line | grep "<title>" | sed 's/<[^>]*>//g')
while [ -z "$info" ]
do
echo "+-------------------+"
printf "| ${RED}15s Over captchu!${NC} |\n"
echo "+-------------------+"
sleep 15
info=$(curl -s $line | grep '<title>' | sed 's/<[^>]*>//g')
done
echo "${info} - ${line}" >> domain_info.txt
time=$(shuf -i 1-10 -n1)
echo "Budes cekat dalsich ${time} sekund"
count=$(($count-1))
echo $count
sleep $time
done < edited_url.txt
